
Check out the official NetApp version of this blog on the NetApp Newsroom!
I’ve been the NFS TME at NetApp for 3 years now.
I also cover name services (LDAP, NIS, DNS, etc.) and occasionally answer the stray CIFS/SMB question. I look at NAS as a data utility, not unlike water or electricity in your home. You need it, you love it, but you don’t really think about it too much and it doesn’t really excite you.
However, once I heard that NetApp was creating a brand new distributed file system that could evolve how NAS works, I jumped at the opportunity to be a TME for it. So, now, I am the Technical Marketing Engineer for NFS, Name Services and NetApp FlexGroup (and sometimes CIFS/SMB). How’s that for a job title?
We covered NetApp FlexGroup in the NetApp Tech ONTAP Podcast the week of June 30, but I wanted to write up a blog post to expand upon the topic a little more.
Now that ONTAP 9.1 is available, it was time to update the blog here.
For the official Technical Report, check out TR-4557 – NetApp FlexGroup Technical Overview.
For the best practice guide, see TR-4571 – NetApp FlexGroup Best Practices and Implementation Guide.
Here are a couple videos I did at Insight:
I also had a chance to chat with Enrico Signoretti at Insight:
Data is growing.
It’s no secret… we’re leaving – some may say, left – the days behind where 100TB in a single volume is enough space to accommodate a single file system. Files are getting larger and datasets are increasing. For instance, think about the sheer amount of data that’s needed to keep something like a photo or video repository running. Or a global GPS data structure. Or Electronic Design Automation environments designing the latest computer chipset. Or seismic data analyzing oil and gas locations.
Environments like these require massive amounts of capacity, with billions of files in some cases. Scale-out NAS storage devices are the best way to approach these use cases because of the flexibility, but it’s important to be able to scale the existing architecture in a simple and efficient manner.
For a while, storage systems like ONTAP had a single construct to handle these workloads – the Flexible Volume (or, FlexVol).
FlexVols are great, but…
For most use cases, FlexVols are perfect. They are large enough (up to 100TB) and can handle enough files (up to 2 billion). For NAS workloads, they can do just about anything. But where you start to see issues with the FlexVol is when you start to increase the number of metadata operations in a file system. The FlexVol volume will serialize these operations and won’t use all possible CPU threads for the operations. I think of it like a traffic jam due to lane closures; when a lane is closed, everyone has to merge, causing slowdowns.
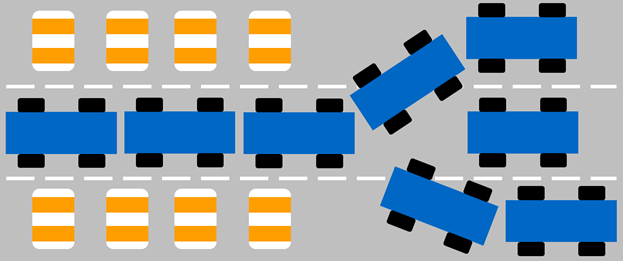
When all lanes are open, traffic is free to move normally and concurrently.

Additionally, because a FlexVol volume is tied directly to a physical aggregate and node, your NAS operations are also tied to that single aggregate or node. If you have a 10-node cluster, each with multiple aggregates, you might not be getting the most bang for your buck.
That’s where NetApp FlexGroup comes in.
FlexGroup has been designed to solve multiple issues in large-scale NAS workloads.
- Capacity – Scales to multiple petabytes
- High file counts – Hundreds of billions of files
- Performance – parallelized operations in NAS workloads, across CPUs, nodes, aggregates and constituent member FlexVol volumes
- Simplicity of deployment – Simple-to-use GUI in System Manager allows fast provisioning of massive capacity
- Load balancing – Use all your cluster resources for a single namespace
With FlexGroup volumes, NAS workloads can now take advantage of every resource available in a cluster. Even with a single node cluster, a FlexGroup can balance workloads across multiple FlexVol constituents and aggregates.
How does a FlexGroup volume work at a high level?
FlexGroup volumes essentially take the already awesome concept of a FlexVol volume and simply enhances it by stitching together multiple FlexVol member constituents into a single namespace that acts like a single FlexVol to clients and storage administrators.
A FlexGroup volume would roughly look like this from an ONTAP perspective:

Files are not striped, but instead are placed systematically into individual FlexVol member volumes that work together under a single access point. This concept is very similar in function to a multiple FlexVol volume configuration, where volumes are junctioned together to simulate a large bucket.

However, multiple FlexVol volume configurations add complexity via junctions, export policies and manual decisions for volume placement across cluster nodes, as well as needing to re-design applications to point to a filesystem structure that is being defined by the storage rather than by the application.
To a NAS client, a FlexGroup volume would look like a single bucket of storage:

When a client creates a file in a FlexGroup, ONTAP will decide which member FlexVol volume is the best possible container for that write based on a number of things such as capacity across members, throughput, last accessed… Basically, doing all the hard work for you. The idea is to keep the members as balanced as possible without hurting performance predictability at all, and, in fact, increasing performance in some workloads.
The creates can arrive on any node in the cluster. Once the request arrives to the cluster, if ONTAP chooses a member volume that’s different than where the request arrived, a hardlink is created within ONTAP (remote or local, depending on the request) and the create is then passed on to the designated member volume. All of this is transparent to clients.
Reads and writes after a file is created will operate much like they already do in ONTAP FlexVols now; the system will tell the client where the file location is and point that client to that particular member volume. As such, you would see much better gains with initial file ingest versus reads/writes after the files have already been placed.
Why is this better?
When NAS operations can be allocated across multiple FlexVol volumes, we don’t run into the issue of serialization in the system. Instead, we start spreading the workload across multiple file systems (FlexVol volumes) joined together (the FlexGroup volume). And unlike Infinite Volumes, there is no concept of a single FlexVol volume to handle metadata operations – every member volume in a FlexGroup volume is eligible to process metadata operations. As a result, FlexGroup volumes perform better than Infinite Volumes in most cases.
What kind of performance boost are we potentially seeing?
In preliminary testing of a FlexGroup against a single FlexVol, we’ve seen up to 6x the performance. And that was with simple spinning SAS disk. This was the set up used:
- Single FAS8080 node
- SAS drives
- 16 FlexVol member constituents
- 2 aggregates
- 8 members per aggregate
The workload used to test the FlexGroup as a software build using Git. In the graph below, we can see that operations such as checkout and clone show the biggest performance boosts, as they take far less time to run to completion on a FlexGroup than on a single FlexVol.

Adding more nodes and members can improve performance. Adding AFF into the mix can help latency. Here’s a similar test comparison with an AFF system. This test used GIT, but did a compile of gcc instead of the Linux source code to give us more files.

In this case, we see similar performance between a single FlexVol and FlexGroup. We do see slightly better performance with multiple FlexVols (junctioned), but doing that creates complexity and doesn’t offer a true single namespace of >100TB.
We also did some recent AFF testing with a GIT workload. This time, the compile was the gcc library, rather than a Linux compile. This gave us more files and folders to work with. The systems used were an AFF8080 (4 nodes) and an A700 (2 nodes).

Simple management
FlexGroup volumes allow storage administrators to deploy multiple petabytes of storage to clients in a single container within a matter of seconds. This provides capacity, as well as similar performance gains you’d see with multiple junctioned FlexVol volumes. (FYI, a junction is essentially just mounting a FlexVol to a FlexVol)
In addition to that, there is compatability out of the gate with OnCommand products. The OnCommand TME Yuvaraju B has created a video showing this, which you can see here:
Snapshots
This section is added after the blog post was already published, as per one of the blog comments. I just simply forgot to mention it. 🙂
In the first release of NetApp FlexGroup, we’ll have access to snapshot functionality. Essentially, this works the same as regular snapshots in ONTAP – it’s done at the FlexVol level and will capture a point in time of the filesystem and lock blocks into place with pointers. I cover general snapshot technology in the blog post Snapshots and Polaroids: Neither Last Forever.
Because a FlexGroup is a collection of member FlexVols, we want to be sure snapshots are captured at the exact same time for filesystem consistency. As such, FlexGroup snapshots are coordinated by ONTAP to be taken at the same time. If a member FlexVol cannot take a snapshot for any reason, the FlexGroup snapshot fails and ONTAP cleans things up.
SnapMirror
FlexGroup supports SnapMirror for disaster recovery. This currently replicates up to 32 member volumes per FlexGroup (100 total per cluster) to a DR site. SnapMirror will take a snapshot of all member volumes at once and then do a concurrent transfer of the members to the DR site.
Automatic Incremental Resiliency
Also included in the FlexGroup feature is a new mechanism that seeks out metadata inconsistencies and fixes them when a client requests access, in real time. No outages. No interruptions. The entire FlexGroup remains online while this happens and the clients don’t even notice when a repair takes place. In fact, no one would know if we didn’t trigger a pesky EMS message to ONTAP to ensure a storage administrator knows we fixed something. Pretty underrated new aspect of FlexGroup, if you ask me.
How do you get NetApp FlexGroup?
NetApp FlexGroup is currently available in ONTAP 9.1 for general availability. It can be used by anyone, but should only be used for the specific use cases covered in the FlexGroup TR-4557. I also cover best practices in TR-4571.
In ONTAP 9.1, FlexGroup supports:
- NFSv3 and SMB 2.x/3.x (RC2 for SMB support; see TR-4571 for feature support)
- Snapshots
- SnapMirror
- Thin Provisioning
- User and group quota reporting
- Storage efficiencies (inline deduplication, compression, compaction; post-process deduplication)
- OnCommand Performance Manager and System Manager support
- All-flash FAS (incidentally, the *only* all-flash array that currently supports this scale)
- Sharing SVMs with FlexVols
- Constituent volume moves
To get more information, please email flexgroups-info@netapp.com.
What other ONTAP 9 features enhance NetApp FlexGroup volumes?
While FlexGroup as a feature is awesome on its own, there are also a number of ONTAP 9 features added that make a FlexGroup even more attractive, in my opinion.
I cover ONTAP 9 in ONTAP 9 RC1 is now available! but the features I think benefit FlexGroup right out of the gate include:
- 15 TB SSDs – once we support flash, these will be a perfect fit for FlexGroup
- Per-aggregate CPs – never bottleneck a node on an over-used aggregate again
- RAID Triple Erasure Coding (RAID-TEC) – triple parity to add extra protection to your large data sets
Be sure to keep an eye out for more news and information regarding FlexGroup. If you have specific questions, I’ll answer them in the comments section (provided they’re not questions I’m not allowed to answer). 🙂
If you missed the NetApp Insight session I did on FlexGroup volumes, you can find session 60411-2 here:
https://www.brainshark.com/go/netapp-sell/insight-library.html?cf=12089#bsk-lightbox
(Requires a login)
Also, check out my blog on XCP, which I think would be a pretty natural fit for migration off existing NAS systems onto FlexGroup.

Pingback: Behind the Scenes: Episode 46 – FlexGroups! | Why Is The Internet Broken?
Pingback: Why Is the Internet Broken: Greatest Hits | Why Is The Internet Broken?
Reblogged this on @greatwhitetec and commented:
Another excellent write up by JP…
LikeLiked by 1 person
So, how is this compared to Infinite Volumes? To me, it sounds a lot like Infinite Volumes, and at least they can do SMB as wel…
LikeLike
Infinite Volume passes all metadata through a single namespace FlexVol constituent. FlexGroups uses all members as potential metadata volumes. Removes file count limitation for a single namespace (2 billion vs 400 billion) and greatly improves performance in high file count environments.
LikeLike
So, do you know how if it’s possible to convert directly a FlexVol to FlexGroups and if not possible how to do to move the data
LikeLike
Not possible yet. Right now, it’s a file copy operation. Tr-4571 covers transitioning to FlexGroup.
LikeLike
Great Work!
What about snapshots, will they be at volume level or flexgroup level ?
LikeLike
Volume level and coordinated across the FlexGroup
LikeLike
Hi. Great post.
Are there any plans to support SMB?
What will happen to Infinite Volume? Looks like FlexGroups is an Infinite Volume done right.
LikeLike
I can’t comment on future support of things, nor on the future prospects of existing products. 🙂
If you’d like a NDA presentation, feel free to contact your sales rep and set one up!
LikeLike
Hi Justin ,
what happen if we loose a shelf , can we still have access to the rest of the FlexGroup?
LikeLike
No. We fence off access until the hardware issue is addressed. When a shelf goes offline, the files and hardlinks won’t be available. Those hardlinks might re-direct to other files, so we want to prevent inconsistencies.
LikeLike
Pingback: What’s the deal with remote I/O in ONTAP? | Why Is The Internet Broken?
Pingback: Will I see you at #NetAppInsight 2016? | Why Is The Internet Broken?
Pingback: One down, one to go. #NetAppInsight | Why Is The Internet Broken?
Pingback: ONTAP 9.1 RC1 is now available! | Why Is The Internet Broken?
Pingback: Post-Insight Wrap-up, Storage Security, and other thoughts! | JK-47
Pingback: Behind the Scenes: Episode 66 – @vMiss33 Gets Her #VCDX On | Why Is The Internet Broken?
Pingback: 9.1RC2 is now available! | Why Is The Internet Broken?
Pingback: Introducing the NetApp FlexGroup Best Practice Guide! | Why Is The Internet Broken?
Pingback: ONTAP 9.1 is now generally available (GA)! | Why Is The Internet Broken?
Pingback: micro blogging – ONTAP 9.1 is GA – ניר מליק
Pingback: The A700s Killing it in the Storage Market | Ruairí McBride
Pingback: [Lesebefehl]: NetApp FlexGroup – DerSchmitz
I’ve just tested Veeam 8 for backing up VMware virtual machines on FlexGroup (ONTAP 9.1). Works like a charm. Veeam makes snapshots from FlexGroup and copying data directly from NFS share just as I expected.
https://www.linkedin.com/hp/update/6250579840366452736
LikeLike
Nice find!
LikeLike
Pingback: Case study: Using OSI methodology to troubleshoot NAS | Why Is The Internet Broken?
Will NDMP backups works with FlexGroups in future? Is it in the road map?
LikeLike
Excellent Post Justin. Thank you!
One question: Does Deduplication in FlexGroup scan all member volumes as if they were a single volume, deduplicating all the blocks globally, or does it analyze and de-duplicate each volume individually?
LikeLike
No, dedupe is done on a per-member volume basis, unless you’re doing aggr-level dedupe. Then it’s across all volumes in the same aggr.
LikeLike
Pingback: How to find average file size and largest file size using XCP | Why Is The Internet Broken?
Are there any plans to use flexgroups as a backup destination from a flex vol via SV?
LikeLike
No plans for that, no. But you will be able to convert flexvol into flexgroup in-place in a future release.
LikeLike